Introduction to NLP Data Annotation: Tasks, Methodologies, and Strategic Importance
Introduction to NLP Data Annotation: Tasks, Methodologies, and Strategic Importance
Natural Language Processing (NLP) stands as one of the most transformative branches of Artificial Intelligence (AI), bridging human language and machine understanding to enhance communication, streamline business operations, and elevate customer experiences. Whether it's a conversational chatbot, sentiment analysis tool, translation app, or voice assistant, the effectiveness of NLP relies significantly on one critical component—Data Annotation.
For AI-driven enterprises and business leaders, understanding NLP data annotation is no longer just beneficial—it's strategically essential. Precision and consistency in data annotation directly influence the performance, accuracy, and overall effectiveness of NLP-powered applications.
In this blog, we'll delve deeply into the essentials of NLP data annotation, explore its core methodologies, examine key annotation tasks, and highlight the strategic benefits of leveraging professional annotation solutions like FlexiBench.
What Exactly Is NLP Data Annotation?
NLP data annotation involves labeling or tagging text and speech data to help AI models accurately interpret and derive meaning from natural language. Annotation essentially converts unstructured linguistic data into structured information that NLP models can process, learn from, and ultimately utilize effectively.
At its core, NLP annotation teaches AI models to recognize context, sentiment, intent, relationships, and meaning—enabling them to interact naturally and intuitively with human users.
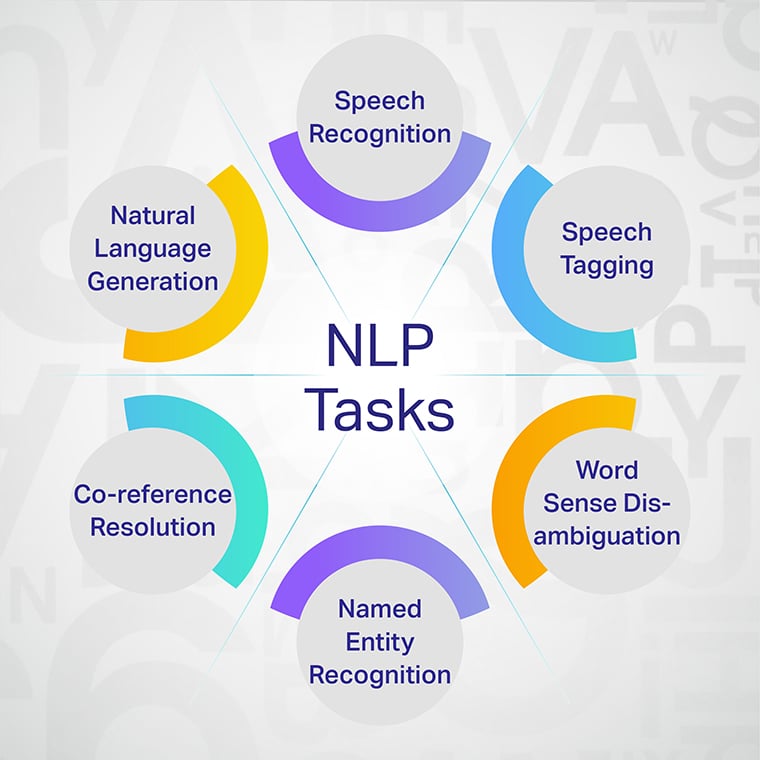
Key NLP Annotation Tasks and Use Cases
NLP annotation encompasses diverse tasks, each tailored to specific linguistic needs and use cases. Here’s a closer look at some of the most prominent NLP annotation tasks:
1. Text Classification
This fundamental NLP annotation task involves assigning predefined categories or labels to text segments, enabling models to classify and categorize documents, emails, customer queries, or product reviews efficiently.
- Example: Email spam detection or sentiment analysis in customer reviews, classifying reviews into "positive," "negative," or "neutral."
2. Named Entity Recognition (NER)
NER annotation involves identifying and categorizing entities such as names, dates, locations, or organizations within unstructured text data.
- Example: Extracting critical details from legal contracts or medical documents, significantly reducing manual processing time and ensuring accuracy.
3. Sentiment Annotation
This task labels text segments according to the underlying sentiment or emotion expressed—such as positive, negative, neutral, or more nuanced emotional states.
- Example: Social media analytics, where businesses measure customer sentiments toward products, services, or brand messaging to inform marketing strategies.
4. Intent Classification
Intent annotation identifies the intent behind user statements, commands, or queries—essential for building efficient conversational AI and chatbots.
- Example: Customer service chatbots leveraging intent classification to quickly determine whether a user wants to "order a product," "return an item," or "speak with customer support."
5. Semantic Role Labeling
Semantic role labeling assigns roles to different parts of sentences to clarify actions, agents, and objects, helping NLP models understand sentence meaning and structure comprehensively.
- Example: Virtual assistant applications interpreting complex instructions, such as scheduling meetings ("Set a meeting with John next Monday at 3 PM").
6. Speech-to-Text Annotation
Annotating audio data involves transcribing spoken content into accurate textual data, enabling speech recognition and natural voice interactions.
- Example: Virtual assistants like Amazon Alexa or Google Assistant that rely on speech-to-text annotations for accurate real-time voice recognition.
Core Methodologies of NLP Annotation
Effective NLP annotation employs several methodologies tailored to data complexity and project needs. Below are common annotation methodologies used to maximize accuracy and efficiency:
Manual Annotation
Human annotators manually label data, providing high-quality and nuanced annotations, especially in complex scenarios demanding contextual understanding.
- Pros: High accuracy, nuanced understanding.
- Cons: Time-intensive, costly at scale.
Programmatic or Automated Annotation
Leverages rule-based logic, large language models (LLMs), and embeddings to annotate datasets automatically or semi-automatically, drastically improving speed and scalability.
- Pros: Cost-effective, scalable, fast.
- Cons: May lack human-level nuance for complex linguistic contexts.
Human-in-the-loop (Hybrid Annotation)
This balanced approach combines automated annotation techniques with human oversight, ensuring scalability, accuracy, and efficiency simultaneously.
- Pros: Optimal blend of accuracy, speed, cost-effectiveness.
- Cons: Requires robust workflow management to balance human and machine tasks effectively.
Strategic Importance of NLP Annotation for AI Companies
Proper NLP annotation isn't merely technical—it's strategically critical to successful AI implementation. Here are significant strategic benefits for your enterprise:
Improved Customer Experiences
Accurate annotation directly enhances chatbot interactions, sentiment analysis, and customer support automation, significantly improving overall customer satisfaction and engagement.
Accelerated Time-to-Market
Quality annotations speed up NLP model training, reducing development cycles. This rapid deployment enables faster ROI realization and agile market adaptation.
Higher Operational Efficiency
Automating repetitive language-processing tasks (customer support, compliance review) via accurately annotated NLP models allows employees to focus on higher-value strategic functions.
Compliance and Ethical AI
Precise NLP annotations ensure AI models are unbiased, fair, and ethically sound—crucial for maintaining regulatory compliance and consumer trust.
Common Challenges in NLP Annotation
While strategically valuable, NLP annotation poses several challenges:
- Annotation Consistency: Ensuring uniform understanding across multiple annotators can be challenging, affecting model reliability.
- Complex Linguistic Nuances: Idiomatic expressions, sarcasm, and context-dependent meanings are challenging for automated systems.
- Scalability and Cost: Manual annotation processes face significant scalability and cost issues as datasets grow exponentially.
- Privacy Compliance: Handling sensitive text and speech data mandates strict adherence to global privacy regulations, complicating annotation workflows.
How FlexiBench Empowers NLP Annotation
FlexiBench offers specialized NLP annotation solutions addressing these challenges comprehensively:
Expert Annotation Teams
FlexiBench’s extensive network of over 70,000 domain-specialized annotators ensures nuanced, consistent, and high-quality annotations, even in complex linguistic contexts.
Advanced Programmatic Annotation
Leveraging state-of-the-art NLP annotation tools powered by rule-based logic, LLMs, and embedding techniques, FlexiBench rapidly annotates massive datasets with exceptional precision and speed.
Hybrid Workflow Model
Our unique human-in-the-loop model combines automated annotation efficiency with human oversight, striking an ideal balance between scalability, cost-effectiveness, and accuracy.
Robust Privacy and Compliance Frameworks
FlexiBench employs sophisticated data anonymization techniques, adhering strictly to GDPR, HIPAA, and other global data privacy regulations, ensuring secure handling of sensitive text and speech data.
Case Study: FlexiBench’s NLP Annotation in Action
A global fintech organization partnered with FlexiBench to enhance their customer support chatbot. Initially, inaccuracies in customer intent recognition reduced customer satisfaction significantly.
Leveraging FlexiBench’s hybrid NLP annotation approach, intent recognition accuracy improved dramatically—from 72% to 96%. Customer engagement increased by 35%, and human-agent involvement decreased, significantly reducing operational costs.
Conclusion: Elevate Your NLP Capabilities with Strategic Annotation
NLP annotation is not just technical—it’s strategically transformative for AI-driven enterprises. Quality annotation boosts model accuracy, enhances customer experiences, ensures compliance, and accelerates AI innovation.
Harness the strategic power of NLP annotation with FlexiBench and transform your linguistic data into exceptional business outcomes.
References
- Gartner, "Emerging Trends in Natural Language Processing," 2023.
- Deloitte Insights, "AI and Customer Experience," 2024.
- Stanford NLP Group, "Latest Advances in NLP Annotation," 2023.
- FlexiBench Case Studies, "Improving Chatbot Accuracy with NLP Annotation," 2024.
Latest Articles
All Articles
A Detailed Guide on Data Labelling Jobs
An ultimate guide to everything about data labeling jobs, skills, and how to get started and build a successful career in the field of AI.

Hiring Challenges in Data Annotation
Uncover the true essence of data annotation and gain valuable insights into overcoming hiring challenges in this comprehensive guide.
.png)
What is Data Annotation: Need, Types, and Tools
Explore how data annotation empowers AI algorithms to interpret data, driving breakthroughs in AI tech.

2nd Floor, C-9, Above PNB Bank,
SDA Market Community Centre, Opposite IIT Delhi Main Gate,
New Delhi, India – 110016