How to Plan Annotation for Long-Term AI Projects (Not Just One-Off Tasks)
How to Plan Annotation for Long-Term AI Projects (Not Just One-Off Tasks)
AI is no longer confined to pilot programs or R&D initiatives. Across sectors, machine learning is becoming a core operational capability—powering search engines, underwriting engines, fraud detection systems, medical diagnostics, and autonomous navigation stacks. As this shift continues, one truth has become increasingly clear: annotation isn’t a one-time project. It’s a continuous input into an evolving intelligence system.
Yet many teams still treat data annotation as a temporary task. They scope it like a campaign—label a batch, train a model, move on. This works for early-stage experimentation, but not for systems that must learn, adapt, and scale over time. For long-term AI success, annotation must be reimagined not as a discrete step, but as a strategic layer in your infrastructure.
In this blog, we’ll explore what long-term annotation planning looks like, why short-term thinking leads to hidden costs, and how enterprise AI teams can architect annotation pipelines that evolve in tandem with their models and products.
Why Ad-Hoc Annotation Strategies Don’t Scale
One-off annotation tasks tend to follow a linear logic: gather data, label it, train a model. But real-world ML systems don’t operate in a linear environment. They operate in live production systems—where data shifts, behavior patterns evolve, and new classes emerge constantly.
This dynamic creates multiple breakpoints for ad-hoc strategies. First, models degrade over time as data distributions shift—a phenomenon known as data drift. If annotation isn’t continuous, retraining suffers and model accuracy drops silently. Second, business priorities shift. What was once a binary classification problem becomes a multi-class, multilingual, or multimodal one. Without a scalable labeling framework, these transitions become bottlenecks.
Third, knowledge is lost. When annotation is outsourced as a one-off job, the labeling logic—how decisions are made, how edge cases are resolved—is rarely documented or retained. As teams grow or change, this gap erodes institutional memory and causes costly rework when models fail and need retraining.
Ultimately, a patchwork approach to annotation becomes the very bottleneck that slows AI innovation. Long-term success demands annotation that scales with the organization—not just with the model.
What Long-Term Annotation Infrastructure Requires
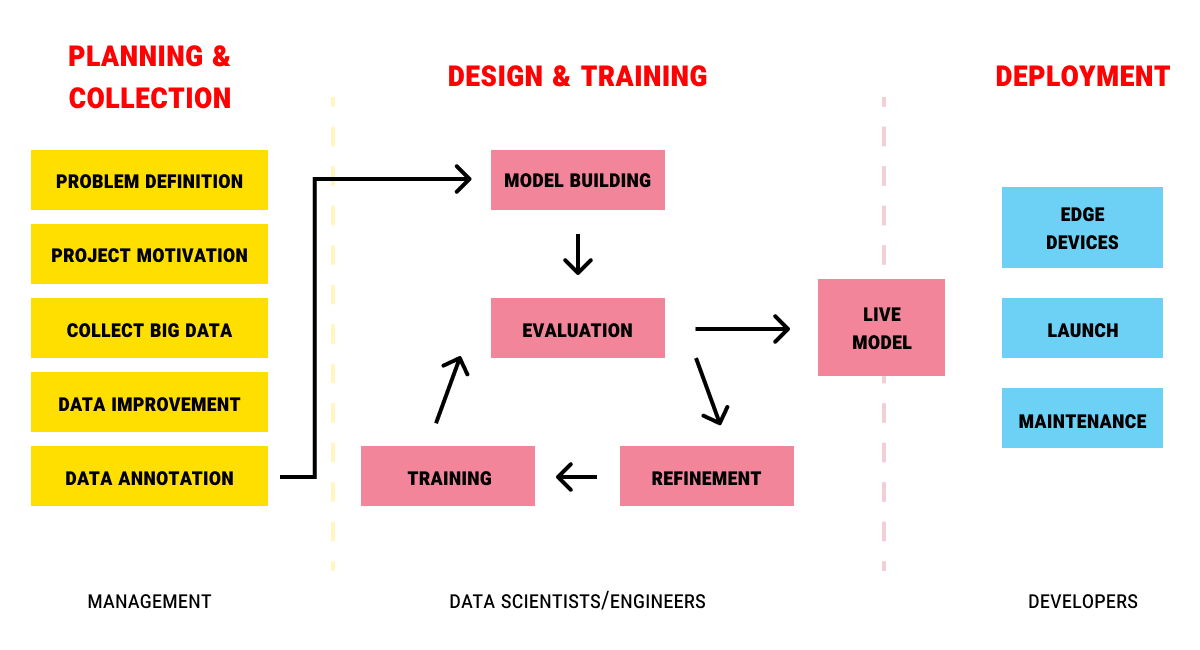
Designing annotation for the long term starts with shifting the mindset—from project to platform. That means establishing workflows, tools, and people structures that support continuous data labeling, revision, and governance—not just one-time output.
The first requirement is a reusable label taxonomy. Labels shouldn’t be reinvented for each model—they should be versioned, auditable, and flexible enough to expand as the system evolves. Taxonomies should be mapped to business outcomes, not just technical definitions, to ensure strategic continuity.
Next is annotation version control. As labels change, so does the logic behind model decisions. Long-term annotation infrastructure must track how, when, and why annotations were modified—so models can be retrained with clarity and compliance.
Human-in-the-loop (HITL) systems are also key. Long-term AI systems must include workflows for human review of uncertain or high-impact predictions. These workflows must loop back into the annotation pipeline—creating a learning system that gets better over time.
Tooling integration is critical. Your annotation system must plug into your ML stack—data ingestion, model training, evaluation, and feedback. Annotation cannot be siloed if the goal is sustained intelligence.
And finally, you need a QA and governance layer. Long-term annotation isn’t just about more labels—it’s about consistently good ones. Without quality assurance, scale introduces entropy. Without governance, annotations lose auditability and traceability—especially in regulated domains.
The Cost of Not Planning for Continuity
Organizations that don’t plan for annotation continuity pay for it in ways that aren’t always obvious. They retrain models more often than necessary. They repeat labeling tasks. They struggle to explain model behavior to regulators. They waste time harmonizing old and new data formats.
Perhaps most critically, they lose data agility. In today’s AI-driven environments, the ability to quickly respond to new threats, new opportunities, or new model requirements is a competitive edge. Teams that don’t plan for continuous annotation can’t respond fast enough—because their labeling infrastructure wasn’t built to keep up.
This isn’t just a technical problem—it’s a business risk. If your AI system can’t evolve because your data strategy is rigid, your competitors will outlearn you.
Designing Annotation into the AI Roadmap
Incorporating annotation into your long-term roadmap means making it a first-class citizen in your ML lifecycle—from budgeting and staffing to tool procurement and performance metrics.
That starts with dedicated ownership. Annotation shouldn’t be delegated as a task—it should have accountable stakeholders who manage workflows, enforce standards, and liaise with ML teams.
Annual planning cycles should include projected annotation needs across model updates, new feature launches, and data quality reviews. This enables budget forecasting and staffing plans to match demand.
Cross-functional integration is also essential. Product teams, compliance leads, and data scientists must collaborate on defining label requirements, reviewing QA metrics, and resolving ambiguity. When annotation is siloed, quality declines and velocity drops.
Data feedback loops should be formalized. When models underperform, it must be clear how those failures map to labeling gaps or data quality issues—and how annotation workflows will adapt.
At FlexiBench, we help clients architect these long-term strategies—not by adding complexity, but by simplifying operations around a durable, scalable core.
How FlexiBench Enables Sustainable Annotation at Scale
At FlexiBench, we don’t treat annotation as a job to be done—we treat it as infrastructure to be built. Our platform supports continuous, multi-format annotation pipelines that evolve with your models—not behind them.
We help teams design modular labeling workflows that can scale, adapt, and self-improve. From reusable taxonomies to integrated QA layers, we provide the foundation that keeps training data aligned with business priorities.
Our teams support both ongoing annotation operations and project-based spikes—enabling clients to balance long-term investment with on-demand flexibility. We maintain task-level version control, annotation audit trails, and performance dashboards that give stakeholders confidence at every stage.
Whether you’re managing five models across three product lines or deploying foundation models with evolving prompts, FlexiBench ensures your data infrastructure is ready to keep up. Because the most powerful models don’t just learn—they keep learning.
Conclusion: You’re Not Just Labeling Data—You’re Building Memory
The organizations winning with AI today aren’t just shipping better models—they’re managing smarter data. And that starts with how they treat annotation.
Short-term projects lead to short-lived intelligence. Long-term success requires systems that learn continuously, correct proactively, and scale sustainably. Annotation isn’t a one-and-done operation. It’s a memory engine. The better you build it, the faster your models adapt—and the more defensible your AI becomes.
At FlexiBench, we help our clients build that engine—not for one sprint, but for the long haul.
References
Google Research, “Continuous Learning and Annotation in Scalable AI,” 2023
Stanford HAI, “Designing Sustainable ML Pipelines,” 2024
McKinsey Analytics, “Enterprise AI Data Strategy and Infrastructure,” 2024
FlexiBench Technical Overview, 2024
Latest Articles
All Articles
A Detailed Guide on Data Labelling Jobs
An ultimate guide to everything about data labeling jobs, skills, and how to get started and build a successful career in the field of AI.

Hiring Challenges in Data Annotation
Uncover the true essence of data annotation and gain valuable insights into overcoming hiring challenges in this comprehensive guide.
.png)
What is Data Annotation: Need, Types, and Tools
Explore how data annotation empowers AI algorithms to interpret data, driving breakthroughs in AI tech.

2nd Floor, C-9, Above PNB Bank,
SDA Market Community Centre, Opposite IIT Delhi Main Gate,
New Delhi, India – 110016