Healthcare Data Annotation: Text, Images, Audio
Healthcare Data Annotation: Text, Images, Audio
AI is quietly reshaping the future of healthcare. From early diagnostics and treatment planning to clinical documentation and virtual consultations, machine learning models are now integrated across the medical workflow. But the foundation of this transformation isn’t just algorithms—it’s data. More specifically, labeled data.
The healthcare domain deals with some of the most diverse, sensitive, and high-stakes datasets in the AI universe. Whether it's an X-ray, a pathology report, a doctor-patient conversation, or an electronic health record (EHR), these assets must be meticulously annotated to unlock their diagnostic potential.
In this blog, we explore how healthcare data annotation works across text, images, and audio, the unique challenges involved, and why it requires strategic investment by healthcare innovators building reliable and regulation-ready AI solutions.
The Spectrum of Data in Healthcare AI
Healthcare data is inherently multimodal. No single data type can provide complete context on a patient's condition. For example:
- A CT scan provides structural information
- A pathology report offers molecular insights
- A clinician’s notes detail subjective observations
- A verbal consultation adds emotional and behavioral context
For AI to understand and learn from this ecosystem, data from all sources needs to be clean, structured, and accurately annotated.
1. Text Annotation in Healthcare: EHRs and Clinical Notes
Text annotation in healthcare primarily involves Electronic Health Records (EHRs), prescription logs, referral letters, clinical trial documents, and physician notes. These texts are often unstructured, filled with abbreviations, and vary by institution or practitioner.
Key annotation tasks include:
- Named Entity Recognition (NER): Identifying and labeling clinical entities like medications, diseases, dosages, symptoms, and procedures.
- Relation Extraction: Mapping relationships between entities, e.g., linking a dosage to a medication or a symptom to a diagnosis.
- Negation Detection: Determining whether a symptom or condition is present or explicitly absent (e.g., "No signs of infection").
- De-identification (PHI Removal): Masking or removing protected health information (PHI) like names, dates, and ID numbers to ensure HIPAA or GDPR compliance.
Strategic Impact: Annotated EHRs are essential for training NLP models that power predictive diagnostics, clinical decision support systems (CDSS), and summarization tools used by physicians to reduce documentation burdens.
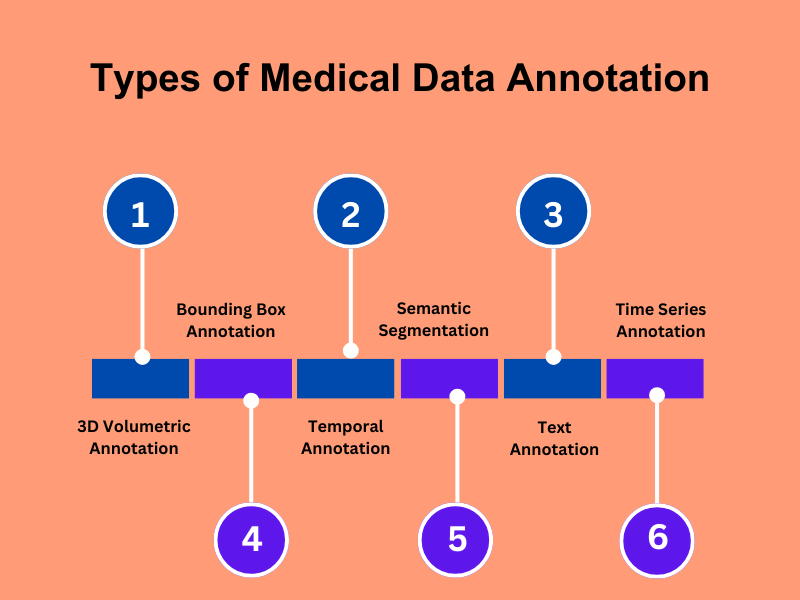
2. Image Annotation in Healthcare: Radiology and Pathology
Medical imaging is at the core of diagnostic AI. Annotation in this domain is both complex and critical due to the precision required and the consequences of model errors.
Typical image data includes:
- X-rays, CT scans, and MRIs
- Histopathology slides
- Retinal fundus photographs
- Ultrasound sequences
Annotation techniques vary based on use case:
- Bounding Boxes & Polygons: Marking visible abnormalities like tumors, lesions, or fractures.
- Semantic Segmentation: Pixel-level labeling of organs, tissues, or pathological regions.
- Instance Segmentation: Distinguishing between multiple instances of similar objects (e.g., multiple nodules).
- 3D Annotation: Layered annotation across slices of CT or MRI scans to reconstruct 3D volumetric data.
Strategic Impact: Properly annotated images train models that assist radiologists in detecting early-stage cancers, identifying fractures, assessing organ damage, and more. Annotation quality directly influences diagnostic accuracy and model generalizability across hospitals.
3. Audio Annotation in Healthcare: Doctor-Patient Conversations
Audio annotation in healthcare is increasingly relevant with the rise of virtual care, telemedicine, and clinical dictation tools. Annotating spoken interactions can reveal not just what is being said, but also how it’s said—providing insight into emotion, urgency, and intent.
Common audio annotation tasks include:
- Speech Transcription: Converting verbal notes or consultations into structured text for further NLP processing.
- Speaker Diarization: Identifying who said what in multi-speaker environments (e.g., doctor, nurse, patient).
- Sentiment & Emotion Tagging: Labeling tone and mood to detect signs of distress or deterioration.
- Named Entity Tagging in Transcripts: Linking symptoms, conditions, or medications mentioned during speech to medical codes.
Strategic Impact: Annotated audio powers ambient scribe technologies, improves virtual care experiences, and supports behavioral diagnostics, especially in psychiatry and elder care.
Key Challenges in Healthcare Data Annotation
Healthcare annotation offers unmatched opportunities—but also carries a unique set of challenges that decision-makers must anticipate:
1. Regulatory Sensitivity
Medical data is heavily protected under laws like HIPAA, GDPR, and HITECH. Any annotation workflow must incorporate data anonymization, access controls, and audit trails from the outset.
2. Domain Complexity
Medical terminology evolves rapidly and varies globally. Annotators need deep clinical knowledge and fluency with systems like ICD-10, SNOMED, and HL7 standards.
3. Inter-Annotator Variability
Two clinicians may interpret the same scan or transcript differently. Annotation projects require consensus protocols, quality checks, and multi-expert validations to reduce subjectivity.
4. Data Volume and Diversity
Hospitals and research centers generate vast, heterogeneous data from different machines, specialties, and demographics. Maintaining annotation consistency at scale demands robust workflows and tooling.
5. Ethical Concerns
Beyond compliance, healthcare annotation raises ethical considerations. Who annotates sensitive data? How is bias identified and corrected? These questions require clear governance and transparency.
How FlexiBench Supports Healthcare Annotation
At FlexiBench, we understand that healthcare data annotation is not just about accuracy—it’s about trust, safety, and long-term impact. That’s why our approach is grounded in precision, domain expertise, and regulatory compliance.
We provide:
- Clinically trained annotators familiar with global medical taxonomies
- Secure infrastructure designed to handle sensitive patient data with full compliance
- Multi-modal workflows that handle text, image, and audio data in parallel
- Built-in anonymization and PHI detection tools
- Custom annotation protocols for radiology, pathology, EHR NLP, and virtual care data
Our annotation solutions integrate seamlessly with AI development pipelines in health tech startups, research labs, and global hospital networks. Whether you're training a model to detect early-stage lung cancer or summarizing doctor-patient consultations, FlexiBench helps you build data foundations that meet clinical standards—without slowing innovation.
The Strategic Imperative
The AI systems of tomorrow won’t just parse numbers or text—they’ll interpret scans, understand medical narratives, and respond empathetically to patient needs. But they can only do this if they’re trained on clean, structured, and carefully annotated healthcare data.
Leaders in digital health, diagnostics, and medical AI must treat data annotation as a strategic layer of their model development—not a backend task. It’s where clinical accuracy, regulatory trust, and technological scalability intersect.
At FlexiBench, we’re proud to power that intersection—quietly, securely, and at scale.
References
- NEJM AI, “Clinical Applications of Machine Learning,” 2023
- World Health Organization, “Guidelines on Health Data Governance,” 2024
- Stanford ML Group, “Labeling Medical Imaging for Deep Learning,” 2023
- JAMA, “Challenges in Annotating EHRs for Clinical NLP,” 2023
- FlexiBench Technical Documentation, 2024
Latest Articles
All Articles
A Detailed Guide on Data Labelling Jobs
An ultimate guide to everything about data labeling jobs, skills, and how to get started and build a successful career in the field of AI.

Hiring Challenges in Data Annotation
Uncover the true essence of data annotation and gain valuable insights into overcoming hiring challenges in this comprehensive guide.
.png)
What is Data Annotation: Need, Types, and Tools
Explore how data annotation empowers AI algorithms to interpret data, driving breakthroughs in AI tech.

2nd Floor, C-9, Above PNB Bank,
SDA Market Community Centre, Opposite IIT Delhi Main Gate,
New Delhi, India – 110016