Build Model-Ready Data
Modern multimodal annotation platform for AI model training data with quality workflows, AI-assisted labeling, and enterprise-grade governance
Multimodal Support
Text, Image, Video, Audio annotation in one platform
AI-Assisted Labeling
80% faster with quality workflows built-in






High-Quality Data Is the Foundation of Every Successful AI Model
Most annotation tools treat labeling as a task. We treat it as data engineering because the right labels determine whether a model succeeds, fails, or never gets deployed.
Annotation Is Not a Service, It Is the Data Engine That Powers AI
At Indika (our parent company), we learned early that models are only as good as the data they train on. The AI landscape shifted, but annotation remained fragmented, inconsistent, and siloed in task-level tools. Flexibench was built to solve this gap: to turn annotation from a checklist activity into an engineering discipline that drives model quality, reliability, and deployment readiness.
Built From Experience, Not Assumption
Existing annotation platforms often treat tasks as isolated jobs, focus on throughput over correctness, and fail to tie labeling to model outcomes. We built Flexibench because we needed something better for ourselves, a platform that integrates deeply with training workflows, enforces consistent ontologies across projects, supports auditable quality pipelines, and gives feedback signals back into model training.
Quality First by Design
High-performance AI requires precise, contextually consistent labels, robust review and QA processes, domain-aware scaffolding and tooling, and iterative refinement feeds into training loops. Flexibench's annotation pipelines are engineered around these principles, not as add-ons: custom schema and ontology versioning, multi-tier review gates, consensus scoring and expert arbitration, model-assisted annotation that reduces error rates.
Annotation That Adapts to the Problem
Flexibench is not 'one interface fits all.' It is configured per use case because labelling requirements vary dramatically between telecom call intent needs, autonomous vehicle perception taxonomies, multimodal medical imaging signals, and voice AI prosody and acoustic event parsing. This flexibility delivers faster time to annotated dataset, fewer review cycles, and stronger model alignment.
Built for Enterprise Scale
Four core modules that work together to deliver model-ready data with quality, consistency, and governance.
Ontology & Taxonomy Management
A clean ontology reduces annotation ambiguity, improves inter-annotator consistency, and powers reliable model training datasets.
AI-Assisted Labeling
Manual labeling alone cannot scale with the data demands of today's models. AI assistance accelerates annotation while keeping human oversight at the center.
Workflow & Quality Assurance
Quality is not an afterthought, it is engineered into every task. Customizable review and rework stages ensure that labeled data meets enterprise quality standards.
APIs & Integrations
Annotation does not happen in isolation. Flexible programmatic access enables automation, pipeline integration, and seamless data movement between annotation and training systems.
Multimodal Annotation Built for Real-World Model Training
Flexibench supports deep, configurable, and scalable annotation workflows across Text, Image, Video, and Audio with tooling designed for quality, governance, and model-aligned outputs.
Text Annotation
Builds richly labeled language datasets that help models understand meaning, intent, context, and safety constraints.
Image Annotation
Teaches vision models to see, segment, classify, and understand visual components with fine-grain detail.
Video Annotation
Enables models to interpret action, sequence, and temporal behavior across frames, not just static images.
Audio Annotation
Structures audio and speech data to power ASR, voice assistants, and acoustic understanding models.
Extend Annotation from Tasks to Strategy
Flexibench is bolstered by internal tools that extend its reach: DataBench for workflow orchestration (with advanced modules like Phonex) and FlexiPod for outcome-driven execution.
DataBench
A central workspace for building, refining, and governing enterprise datasets
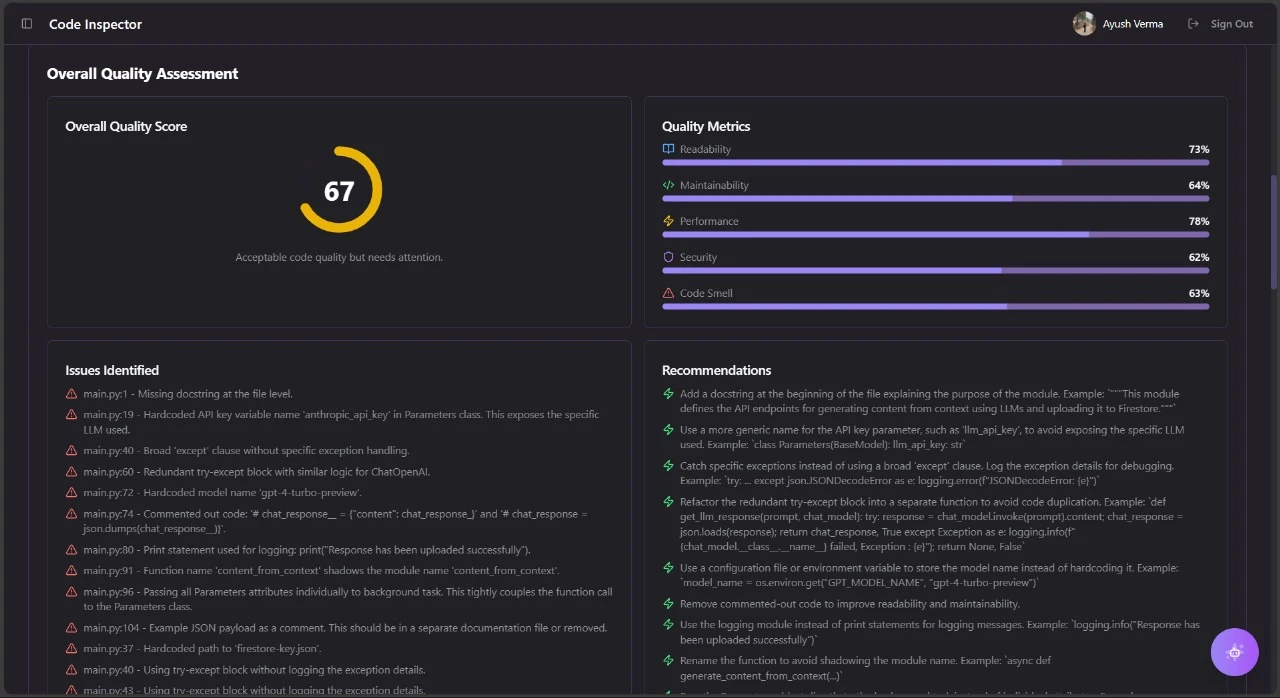
DataBench is where annotation becomes science and strategy, not just tasks. It brings together collection, labeling, review, experiment integration, and dataset iteration into a single workspace.
WHY IT MATTERS
Today's AI systems require structured datasets with governance, repeatability, and metric visibility. DataBench empowers teams to design workflows, enforce standards, measure progress, and iterate with auditable quality checkpoints.
CORE CAPABILITIES
- Unified Dataset Repository: Single source of truth for all annotation work
- Workflow Builder: Configurable pipelines from raw input to production-ready dataset
- Labelset & Schema Manager: Reuse ontologies across domains and projects
- Review Dashboards: Monitor consensus scores, disagreement hotspots, and tooltip metrics
- Experiment Integration: Export labeled datasets with tags and metadata to training pipelines
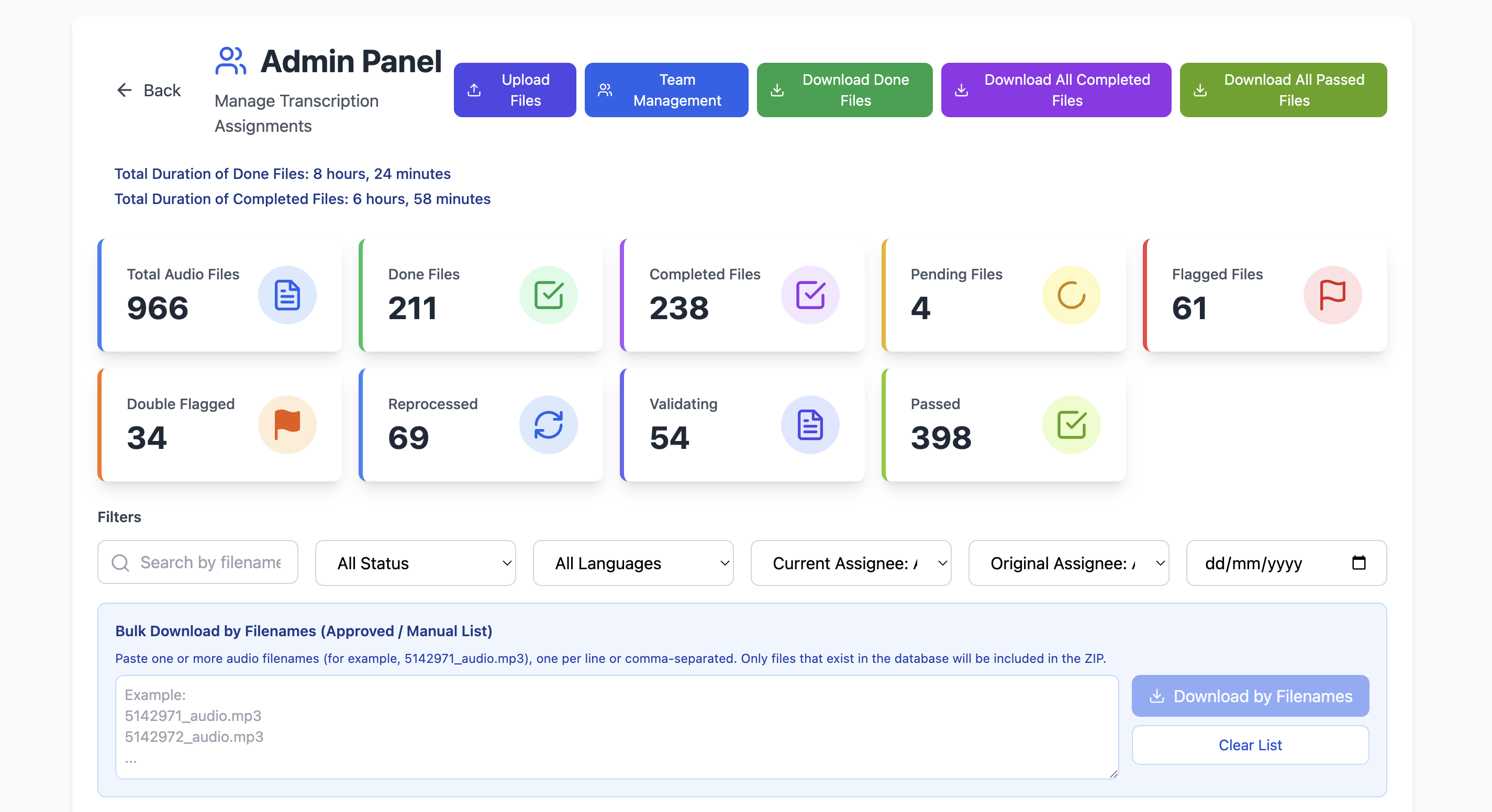
FlexiPod
Cross-functional talent pods that take full ownership from strategy to execution
Learn moreTrusted by Data-Driven Teams Worldwide
Flexibench enables organizations to produce higher fidelity datasets, more consistent models, and faster iteration cycles ensuring annotation is a force multiplier, not a bottleneck.
Datasets Annotated
Enterprise datasets processed across industries with enterprise-grade quality workflows.
Quality Score
Average annotation quality score across all projects with multi-tier review pipelines.
Time Saved
Manual annotation hours saved through AI-assisted labeling and automated workflows.
Annotation Use Cases Across Industries
Explore real-world annotation workflows that solve enterprise challenges across industries and modalities.
Clinical Notes Entity Extraction for Diagnostics
PROBLEM
Clinicians struggled to surface key medical entities in unstructured clinical text.
Pedestrian Occlusion Track Annotation for AV Safety
PROBLEM
Autonomous systems misidentified partially occluded pedestrians.

Voice Assistant Intent Classification
PROBLEM
Voice assistants misclassified user intents, leading to poor response accuracy.
Annotation with Accountability
Built for Trust, Consistency, and Deployable AI. High-quality labels are non-negotiable for reliable models. Flexibench embeds robust quality engineering and governance into every annotation workflow.
Benchmarking and Gold Standards
Flexibench lets teams define benchmark examples as ground truth. These benchmarks act as reference points for labeler performance, training calibrations, and automated QA checks.
Consensus Scoring Across Annotators
Consensus mechanisms evaluate agreement between multiple annotators on the same data item. A high consensus score indicates strong alignment, while lower scores trigger review and adjudication workflows.
Multi-Stage Review Pipelines
Flexibench supports flexible review workflows: initial annotation pass, peer review or expert adjudication, automated gated QA rules, and escalation for ambiguous or high-risk items.
Start Building Model-Ready Data Today
Whether you want a demo, a consultation, or onboarding support, our team is ready to help you succeed with Flexibench.
Talk to Sales
Get a tailored demo and learn how Flexibench can fit your annotation needs.
Request a Demo
Choose a time and let us walk you through the platform.
What Our Clients Say
Trusted by leading AI teams worldwide
Frequently asked questions about Flexibench
Find answers to common questions about our annotation platform, capabilities, and how it can help your team. Can't find what you're looking for? Contact us.